- Direct payment (XMR)

BookGPT - Uncensored AI Powered Ebook Search Engine With Over 200Million Ebooks 
Description
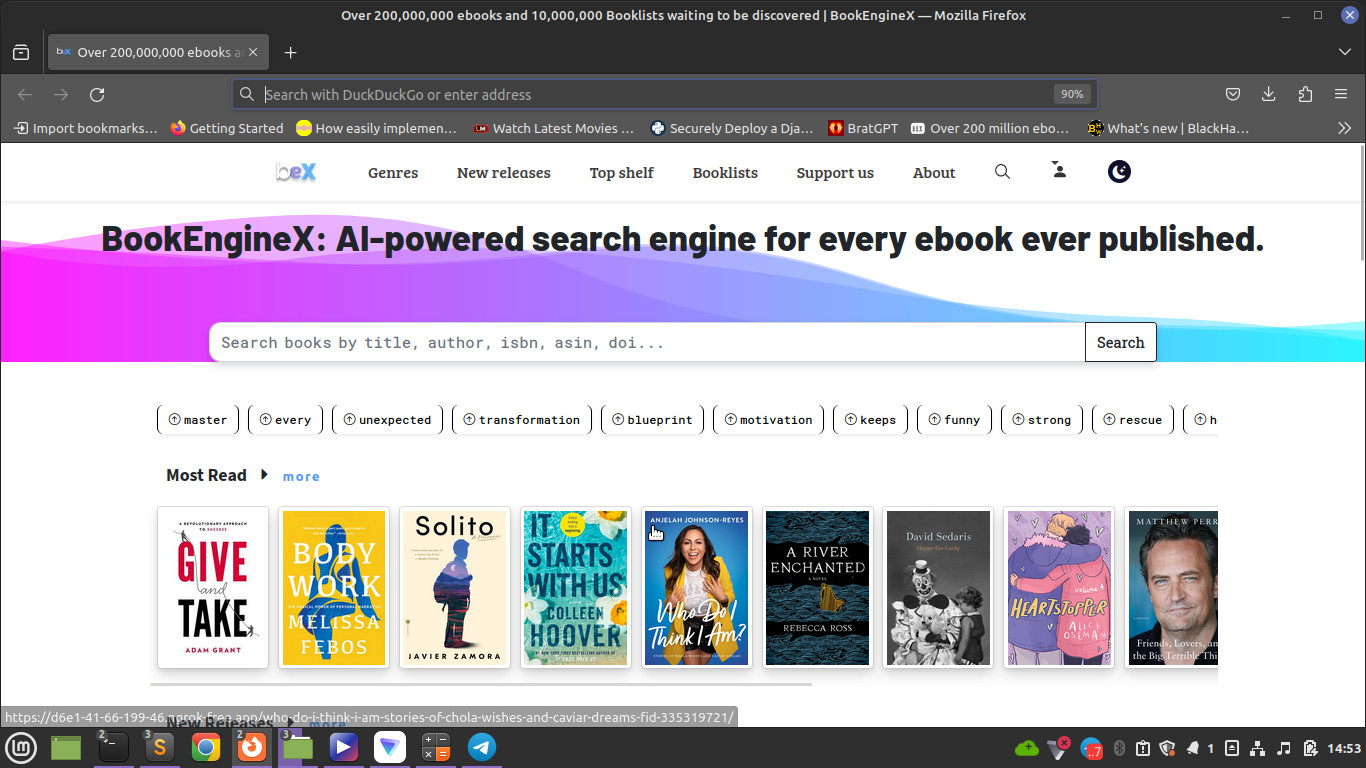
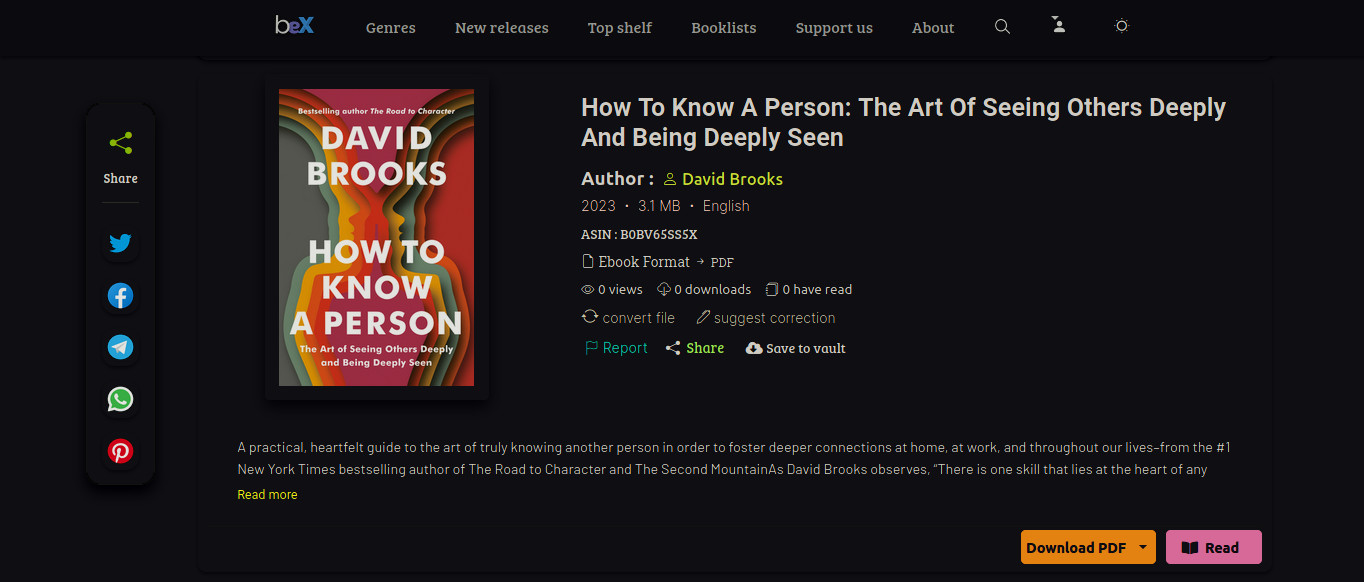
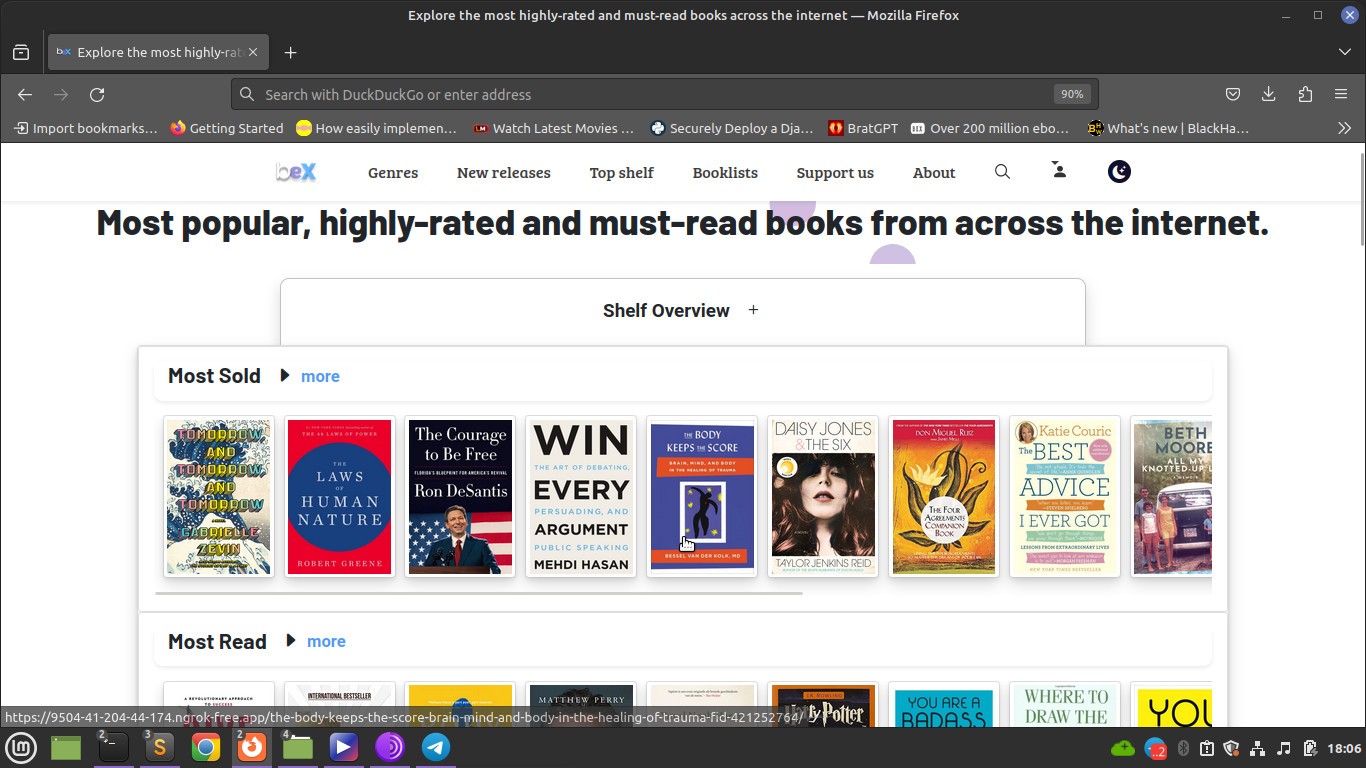
BookGPT (formaly BookEngineX) is an advanced uncensored AI powered search engine providing free access to every ebook, article, journal and research paper ever published on the internet. BookGPT currently has indexed over 200 million ebooks and counting.
Features:
Omni-Search: Instantly search for books from multiple sources in real-time.
Bexco Token: Expand storage capacities, access advanced AI searches, and engage with authors.
Top Shelf: Discover the most sought-after books from various platforms.
Personalized Recommendations: AI-driven suggestions based on your reading activity.
Ebook Collections: Explore and share diverse collections created by fellow book lovers.
Personal Vault: Save and access your favorite reads anytime, anywhere.
EReader: Read any book in realtime without downloads.
List Of Potential Beneficiaries of This Project:
Book Enthusiasts: Readers seeking diverse literature and personalized recommendations.
Researchers and Academics: Access to a wide array of indexed books and quick material retrieval.
Programmers and Developers: Learning resource for the technology stack behind AI-powered search engines.
Students: Find relevant academic resources for research projects.
Authors: Engage with readers and understand preferences using Bexco Tokens.
Educational Institutions: Explore technology and ethical considerations in AI tools.
Programmers and Developers: Learning resource for the technology stack behind AI-powered search engines and training AI models.
Blockchain and Cryptocurrency Enthusiasts: Engage with digital assets through Bexco Tokens.
After purchasing, you will automatically be able to download Book_GPT.zip (41 MB).
Category: Software
Tags: ebooks, articles, research, journals, uncensored, pdf, search engines, AI powered, 200M+, bookgpt, free knowledge, web scrapping
Published on: June 17, 2025
Views: 22
Legal Notice: Buyers and sellers are responsible for complying with all applicable laws in their jurisdictions. XmrBazaar does not verify legality and assumes no liability. Peer-to-peer cash-for-crypto trades are permitted if not conducted as a business and are compliant with local laws; otherwise, sellers must hold any required licenses or registrations. Listings involving fraud, violence, child exploitation, or other clearly illegal goods or services are strictly prohibited and will be removed once identified. Users are encouraged to report unlawful listings.
About the trader
N/A
N/A
-----BEGIN PGP PUBLIC KEY BLOCK----- mDMEAAAAABYJKwYBBAHaRw8BAQdAb/8CNWk/ZKmVzgtfNRmkxGTzqxl6W2E7d9sj nkjZeDe0GGFscGhhZGV2MDFAeG1yYmF6YWFyLmNvbYiUBBMWCgA8FiEEGUC0cJep zz1xwHHhiz+8JPqcJw4FAgAAAAACGwMFCwkIBwIDIgIBBhUKCQgLAgQWAgMBAh4H AheAAAoJEIs/vCT6nCcO8+ABAJ3yVjU0/yEG2+q2GyApzQyM0flGWEE79PuiiOVn QlRjAQCBDGNw6WUKumQ+MC3tjo9mje8QCo2wfO1xJBM1HIvMDrg4BAAAAAASCisG AQQBl1UBBQEBB0CM/sXCrMS4HXttEw4Pe+Gx2dU1CtmZcLggMNLhdD6vYgMBCAeI eAQYFgoAIBYhBBlAtHCXqc89ccBx4Ys/vCT6nCcOBQIAAAAAAhsMAAoJEIs/vCT6 nCcOiX0A/0nB2pDZQ5I7BfIUkgcYjAnPCk/c8FXUTQ8p6ArWiKh3AQDeZ1V429Xe JmEoJpdKi6lZTSX/FRsGBsuKlPW1MkFBBQ== =3YVL -----END PGP PUBLIC KEY BLOCK-----
Actually ana's archive is among the critical data sources of this project; we scrape from Zlibrary, springer, Sci-Hub, oceanofpdf, oapen, libgen, pdfsworld, pdfdrive, Just Another Library (deepweb) to say a few and other millions of sources I would like not to say here. We have a very advance progressive AI scrappers (automated agents), that searches the web (deepweb included) and create crawlers for potential sources, adding it to the indexes.
To make few worrying clarifications about ana's archive first:
Ana's achieve have started complying with authorities and removing books from their indexes, these are dmca complaint related files, and just with enough time chunk of rare, costly and banned books will be off on ana's archive indexes because from my experience publishing companies never rest until their books are off your page. I'm saying this because I have hosted my platform a couple of times and has been taking down or hacked aggressively.
Ana's Archive also seems to have pay-as-you go model which was establish last 3years. This is not necessarily paying for access but you have to pay for speedy, safe and stable downloads, some books takes hours to download (this applies to only free users) because of torrent seeding issues sometimes.
Now back to BookGPT:
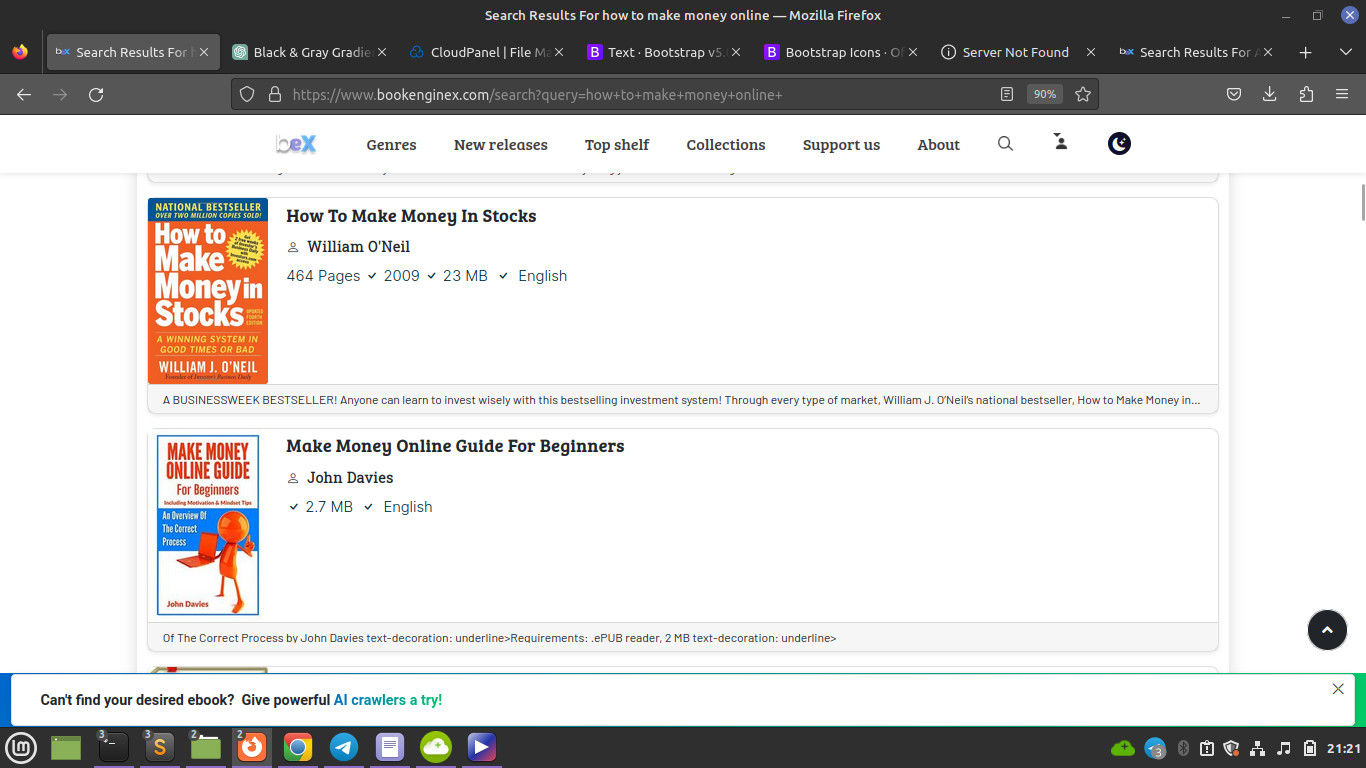
The most notable difference is that this project is uncensored (brutally getting you exactly whatever you want without any sort of regulation or whatever, any book ever).
You don't also have to wait for a particular book (waiting until our scrappers index it) if is not readily available on the platform, you can simply deploy AI crawlers to search the web in realtime with your query and get you your hard-to-find book with just a click (takes less than 1 minute and this never fails).
Another impactful difference is that you can set this project locally and have the entire internet of books, journals, articles and research papers on your device without being worried about being watched or DMCA take downs because you're invisible (yeah you don't even exist). your traffic is also routed through the tor network so that your IP addresses are not exposed.
Consider this as a shadow library (maybe ana's archive but 100% uncensored) but on your computer which no one knows about, and without any regulation or restriction but get you what you want from the web through tor network and do it unapologitically.
And lastly this project comes with the actual source code, you can experiment with it anyway you want and do with it as you please.